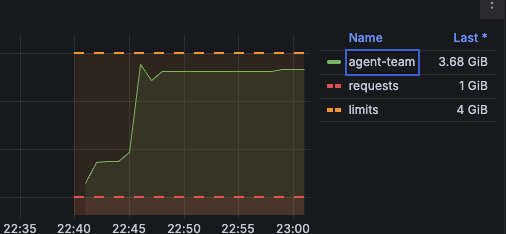
We have a Team with 3 included agents.
All agents have the same configuration, here are some outlines:
Team:
Team(
name=“Team of agents”,
team_id=“team_id”,
mode=“coordinate”,
model=OpenAIChat(id=AGENT_MODEL),
members=[
agent1,
agent2,
agent3,
],
tools=[ReasoningTools(add_instructions=True)],
instructions=,
markdown=True,
enable_agentic_context=False,
add_datetime_to_instructions=True,
debug_mode=AGENT_DEBUG_MODE,
show_tool_calls=AGENT_SHOW_TOOL_CALLS,
stream_intermediate_steps=AGENT_SHOW_TOOL_CALLS,
memory=Memory(
db=PostgresMemoryDb(
table_name=“leader_memory”,
db_url=DB_URL,
schema=DB_SCHEMA
)
),
show_members_responses=True,
enable_user_memories=True,
enable_session_summaries=False,
storage=storage,
share_member_interactions=False,
add_history_to_messages=True,
read_team_history=False,
num_history_runs=1,
)
Agent(
name=“Agent 1”,
role=“Role of Agent 1”,
model=OpenAIChat(id=AGENT_MODEL),
tools=tools,
description=“Tou are the agent N1”,
instructions=instructions,
show_tool_calls=AGENT_SHOW_TOOL_CALLS,
stream_intermediate_steps=AGENT_SHOW_TOOL_CALLS,
debug_mode=AGENT_DEBUG_MODE,
search_knowledge=True,
update_knowledge=False,
memory=Memory(
db=PostgresMemoryDb(
table_name=“agent1_agent_memory”,
db_url=DB_URL,
schema=DB_SCHEMA
)
),
enable_user_memories=False,
enable_session_summaries=False,
knowledge=knowledge_base,
add_history_to_messages=True,
num_history_responses=1,
read_tool_call_history=False,
)
Also default storage:
storage = PostgresStorage(
table_name=“agent_sessions”,
db_url=DB_URL,
schema=DB_SCHEMA,
mode=“team”,
auto_upgrade_schema=True
)
The configuration is default. Memory leak is visible permanently the more request is made the bigger the memory usage gets without dropping.
Recently we tried to explore the heap dumps, unfortunatelly not much. We discovered that 80% of the memory is used by List and Dict.
Would really appreciate your help.